

I recently observed that most of a client’s backlog items had 5-point estimates. A colleague tweeted it, and an 180+ Twitter storm followed. This article explains the phenomenon, and why no one should call the police.
Introduction
To manage capacity, forecast delivery dates and motivate architectural thinking, we often ask development teams to estimate proposed work. We were curious whether group dynamics cause statistical patterns in estimates. If so, can we reduce effort estimating detailed backlog items, especially in early forecasting, before we are really certain about what we might do?
Here we examine one organization’s data to look for signals and patterns. Our analysis is too anecdotal to provide conclusive recommendations for other groups and other individual teams, but it is highly likely that these patterns exist elsewhere. We illuminate biases and patterns in estimation behavior. We seek greater discussion on estimation behavior, with the goal of better forecasting with less effort.
This article has three parts
- Introduction to Story Point Estimation and other techniques currently used by teams
- A presentation of data and patterns seen by the author as part of a recent client engagement
- Discussion and initial thoughts on causes of the observed patterns
Story Point Estimation
For Agile teams who estimate, story points have become a popular unit to measure estimated effort. Agilists invented an artificial unit of “story point” to distance effort estimation from time estimation, and to render comparisons between teams more obtuse. For its primary purpose, allowing people to compare the estimated team effort of different items, story points work fine.
The story point metric also provides a way to limit work to avoid overwhelming the team’s capacity, and to forecast future team progress. The story points completed over time provides “velocity”, which usually correlates with the team’s near-term capacity. Velocity can then used for medium or long term projections, with diminishing accuracy as time frames increase. Our case study used story points for both purposes.
How Teams Estimate using Points
No standard method dictates how teams assign story points to a work item. Estimation generally occurs in specific meetings between the team and the “Product Owner” (the author of the work items). Having the Product Owner accessible during estimation helps the team quickly clarify work intent and acceptance criteria before estimating. Often these discussions turn to how splitting a large work item into smaller work items that incrementally build functionality and spread the invention risk.
To estimate new work items consistently with historical work, teams often compare them against previously estimated and completed work items (“reference stories”). Teams can estimate faster by quickly finding reference stories that bracket the new work item’s estimated effort. Reference stories help normalize estimates and learn from history. Some teams take comparative estimation further by spreading a large number of stories on a table and clustering them in groups of similar effort, assigning a point estimate value to all stories in a “pile.” This process, called “Bulk Estimation” (see http://senexrex.com/bulk-estimation/), helps teams focus on what work is larger and smaller in effort from other work. For prioritization trade-off decisions, this early information helps do high-value low-effort work before high-effort low-value work.
Agile and Lean Startup methods and practitioners promote smaller work items. Teams work hard to split work into acceptably small items. This helps the team deliver smaller increments (with shorter lead time) and allows deferring complex features that may change after customers try the simpler features. In my experience, stories are often split to smaller units but rarely combined into larger units for work being attempted in a sprint cycle.
All teams in this article biased towards smaller pieces of work and estimates in the presence of the Product Owner who helped split work if it was too big.
Fibonacci Scales
To avoid team members getting too detailed in their estimation with an open ended story point scale to choose from, some teams restrict the story point options to a subset. The most commonly chosen subset of estimation values follows the Fibonacci Scale. The logic is that the “next” sizing option is 50% larger than the previous and this is about as good a guess as likely possible given the information on-hand and the uncertainty surrounding the technical and system risks.
Pure Fibonacci is where the next number is the sum of the previous two numbers in the sequence, such as: 1, 2, 3, 5, 8, 13, 21, 34. This is often modified by software teams as 1, 2, 3, 5, 8, 13, 20, 40 for “simplicity,” however this author is not exactly sure why its perceived simpler, it is just different.
By restricting to a smaller set of options, any continuous pattern in allocation is replaced by discrete stepped patterns. When people estimate using these options they are guessing which size option the story is closest too. This satisfies the intended purpose of discerning which pieces of work are more effort than others and by how much in discrete steps.
Modified Fibonacci scales were used by all teams in this article, although Team C used a mix of traditional and modified Fibonacci values in its story point estimates presumably in error.
Planning Poker
Planning Poker is a game to get team members to discuss different estimation perspectives. Each team member estimates privately, then all reveal their estimates simultaneously. This reduces anchor bias. Planning poker was used by all teams in this article.
- The Product Owner provides a work item description
- The team discusses the work item with the author to clarify and refine
- When the team is ready, team members who may work on the item reveal their estimates in unison (on the count of three). Revealing in unison avoids one estimator anchoring the group. Various ways of achieving this unison vote, pre-printed playing cards with Fibonacci numbers on them, peoples fingers in the air, text in a chat window, even just shouting
- The group discusses the differences. For example “Joe, you say a 20 but everyone else says a 5, do you know something we don’t about that code?” Discussion continues until everyone in the group agrees to a number, or the facilitator chooses the highest remaining if consensus is taking too long
Planning Poker is fast when team members agree, and generates discussion when team members disagree; It avoids anchor bias among team members. Newer team members learn through during discussions why such a range of estimates were initially suggested.
More information on Planning Poker and its motivation Wideband Delphi Estimation can be found here:http://en.wikipedia.org/wiki/Planning_poker
http://en.wikipedia.org/wiki/Wideband_delphi
Expected Patterns
I anticipated pattern arising from these estimation techniques, which would appear in the histogram and summary statistics of story point estimates assigned by teams.
- The curve will be left-weighted (have a longer right tail).
- The Mode would be to the left of the range center.
- The rate of decay after the Mode would be exponential.
All teams under study used the modified Fibonacci sequence of 1, 2, 3, 5, 8, 13, 20, 40, 60, 100. 40, 60 and 100 were only used in special cases, for most purposes, 20 was the highest estimate given by teams, other numbers were “we don’t need to know yet, but its big”. Given this backdrop, the following pattern was expected –
a. Median would be 5 points.
b. Mode would be 3 or 5 points (central or first below middle option).
c. Average (Mean) would be 5 story points.
My reasoning for these expected patterns is based upon observing the subtle pressure for smaller pieces of work versus larger items. It was rare that any effort was applied to understanding work greater than 20 points, in fact, placing a 100 point estimate should mean higher density lower estimate groups.
Utilization of a modified Fibonacci numbers influenced patterns. Just by limiting the possible values to a subset of groups, estimators are forced to make a sequence of binary decisions rather than an absolute estimate. When this scale isn’t linear, the distributions should not be expected linear.
Observed Estimation Patterns
This article describes three different teams chosen from an organizational unit of approximately 80 teams. The teams chosen are of different disciplines. A management process change team (team A), a typical software development team (team B), and a team who performs estimation using a relative bulk estimation technique (team C).
The summary of the Mean, Standard Deviation and Median of the three teams is –
| Team | Mean | SD | Median |
|---|---|---|---|
| Team A | 4.4 | 3 | 5 |
| Team B | 5.4 | 6 | 5 |
| Team C | 5.7 | 5.5 | 5 |
Sampling Method and Statistics
Estimates were pulled from an electronic tracking system. One data field for proposed and completed work held story point estimates. This data was already numeric. In addition to the estimate field, the date the item was created, the date the item was marked as resolved (if it was resolved), and a field indicating what type of work item the entry represented. This data was captured in Excel for statistical analysis and analyzed with EasyFit from Mathwave to obtain summary statistics and histograms.
Team A
Team A is a process change management team of approximately six people that delivered no technical code. Team A produced material for assisting the adoption of Scrum within the organization. Team A had 165 samples total. One sample was removed because it was 55 and appeared as a typographical or transcription error. 164 samples were analyzed, there was one value of zero.
Figure 1 – Statistics for Team A Story Point Estimates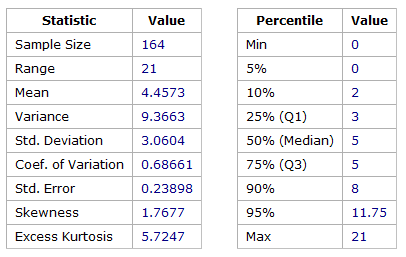
Figure 2 – Histogram for Team A Story Point Estimates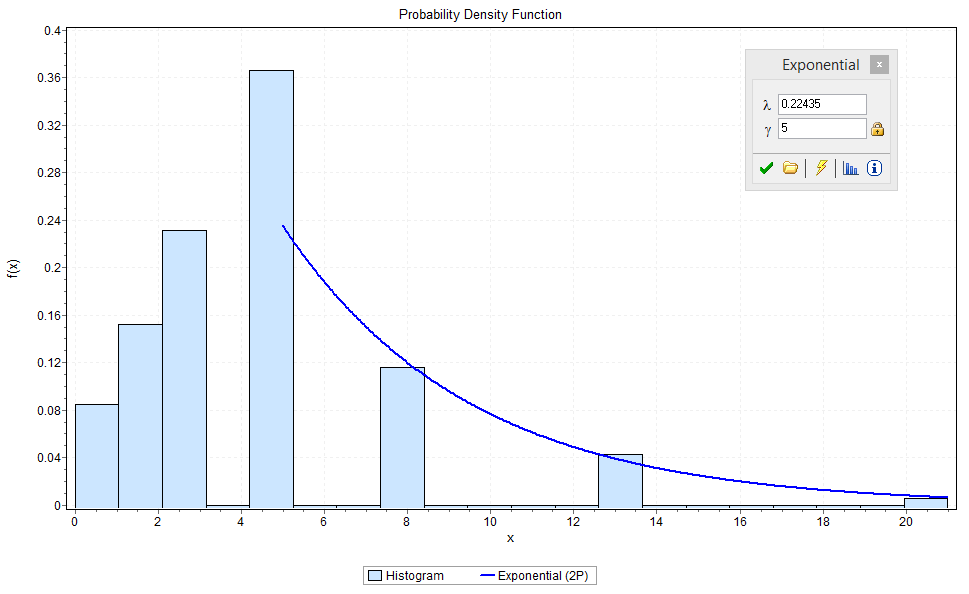
Team A showed the common traits expected for teams estimating using a Fibonacci sequence. Meadian and Mode values were in fact both 5 points, and the higher values of 8, 13 and 20 decayed exponentially when plotted on a linear scale.
Team B
Team B is a software development team with little UI coding. They have a team size of approximately 12 people broken into two smaller groups. Data for this team can be analyzed in more detail. Team A produced no defects (they did, but new work items were created to fix errors and omissions), Team B did record the work item types into categories. This allows analysis of “work” and “defects” separately and combined.
Figure 3 – Statistics for Team B Story Point Estimates – All (work & defects)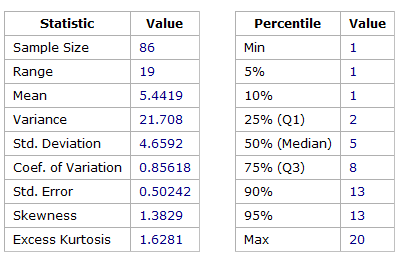
Figure 4 – Histogram for Team B Story Point Estimates – All (work & defects)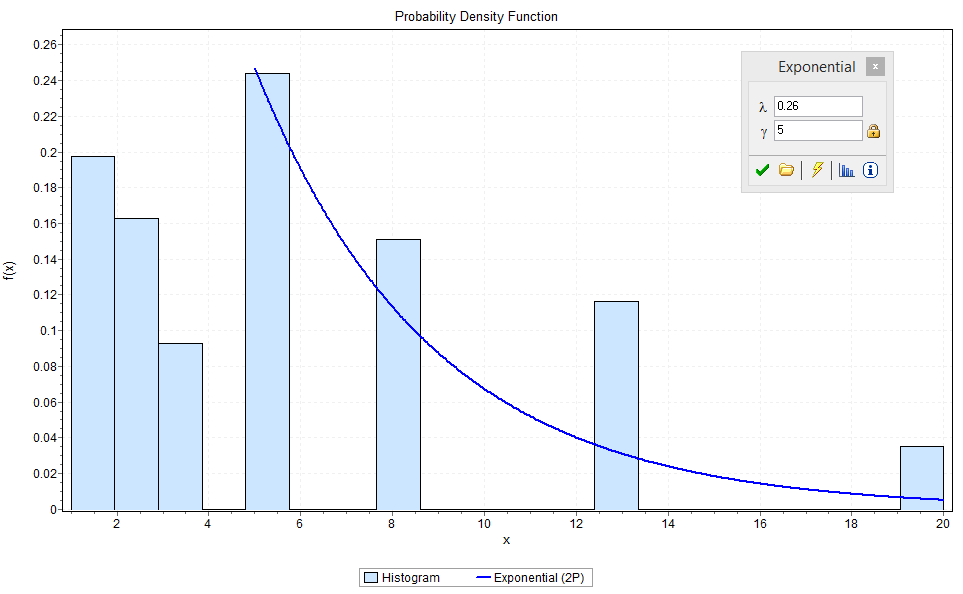
Figure 3 shows the expected result for Mode, Median and Mean values being closest to 5 story points, but the histogram shown in Figure 4 was not expected. Although the 5 story point result was as expected curiosity demanded understanding why this team’s distribution wasn’t following the anticipated decay rate. A hypothesis was that Defects are often smaller fixes and may explain the high occurrence rate of the lower values, especially those of 1 story point.
Figure 5 – Histogram for Team B Story Point Estimates – Defects Only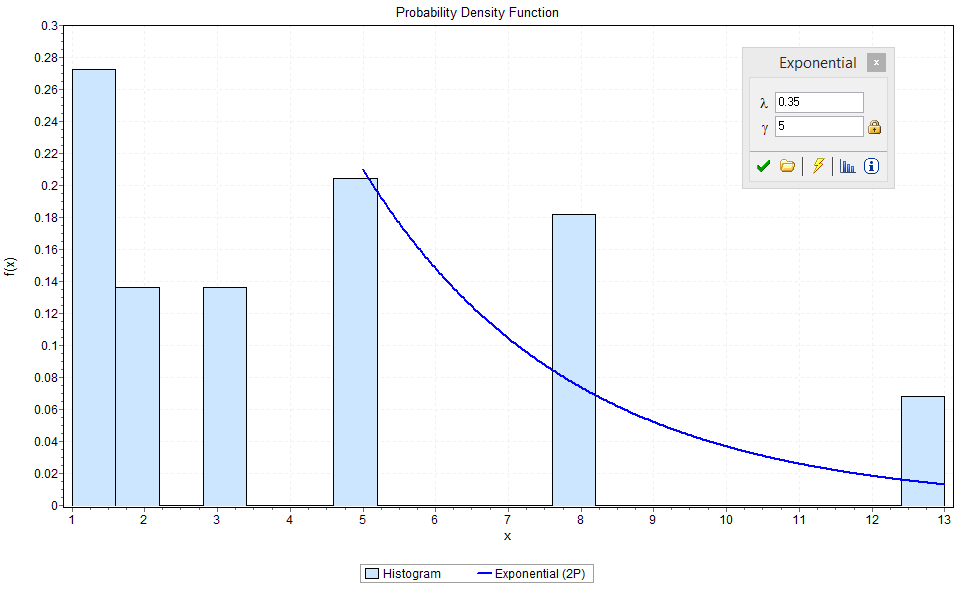
Figure 5 does demonstrate that defects follow a specific pattern where 1 story point is the Mode. Also notable is the occurrence rate of the 8, 13 and 20 story point defects. It would appear that Defects whilst left weighted slightly, the distribution is more uniform. The Mean value for defects is 4.3 points, and the Median is 3 a shown in Figure 6.
Figure 6 – Summary Statistics for Team B Story Point Estimates – Defects Only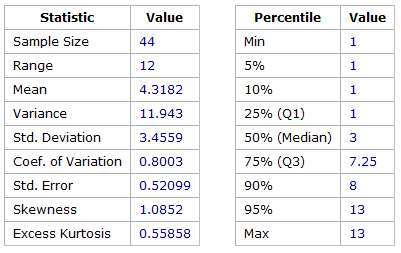
For completeness, Figure 7 and 8 show the summary statistics and histogram of the planned work. When faced with a forecasting situation, the work plays the majority role in most cases as it is the only work known in advance of the project. For this work there is a sizable number of 20 point estimates. Team B rarely undertook 20 point stories in their sprints, but carried a larger number than expected 20 point stories in their backlog that were split closer to when they were going to be started. This pattern is encouraged from a process perspective because some of this work may never be attempted and premature splitting is considered a form of waste.
Figure 7 – Descriptive Statistics for Team B Story Point Estimates – Work only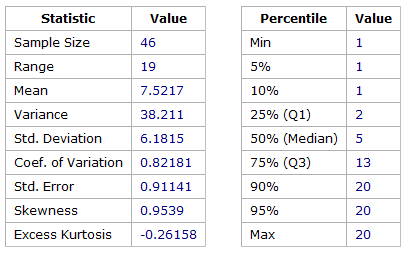
Figure 8 – Histogram for Team B Story Point Estimates – Work only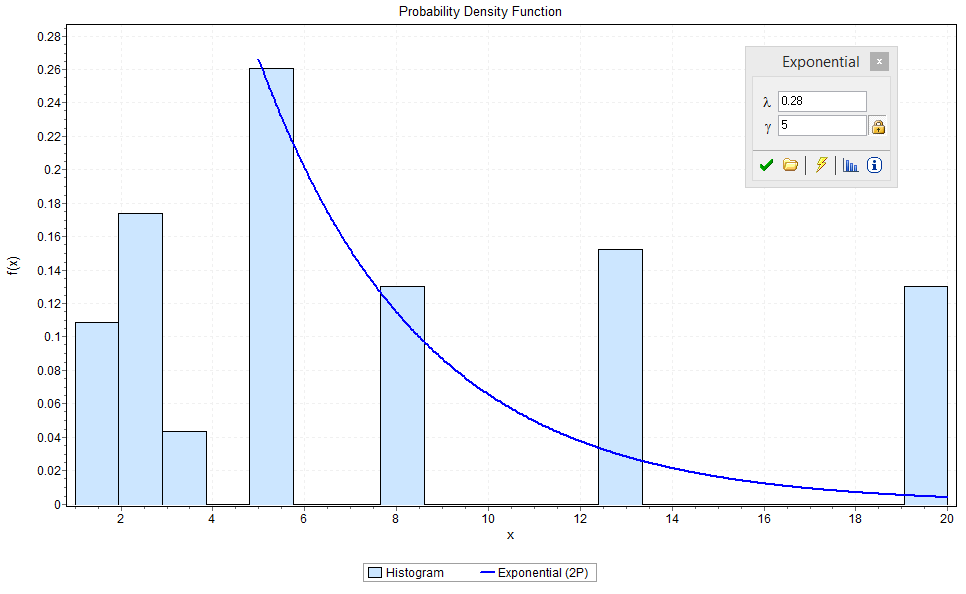
Team C
Team C is a software development teams that builds internal tooling. Team size is approximately 10 people. Team C also has recorded defects and work. The defects and work statistics followed the same pattern as Team B, where defects had a higher Mean value (6.7 average) but shared the Median of 5 story points. The Mode for Team C was 3, lower than the expected value of 5 points.
The exponential decay was present after the Median value for the next unit of 8 points, but those estimates higher than that failed to follow the same exponential pattern. Team C carries higher story point estimates in the backlog.
Figure 9 – Descriptive Statistics for Team C Story Point Estimates – All work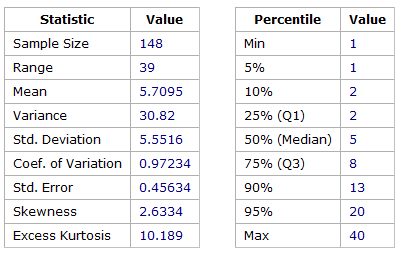
Figure 10 – Histogram for Team C Story Point Estimates – All work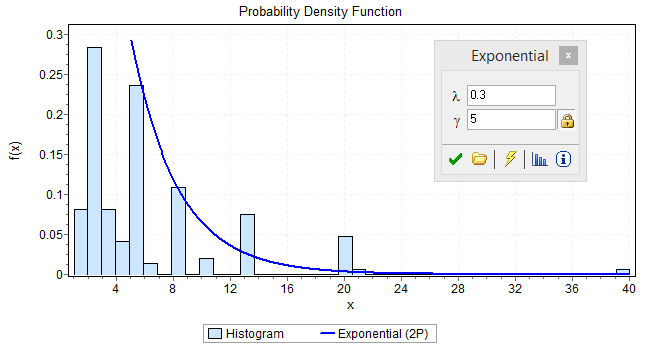
Conclusion
It is no surprise that story point estimates follow particular patterns. The patterns are influenced not only by the work effort, but also the process and the estimation techniques used.
If it is found these patterns are predictable, this knowledge can be used for practical purposes –
- Checking the validity of future estimation sessions. Failure to follow a similar pattern may be an indicator of reduced forecast utility
- Medium to long term forecasts may be possible without complete estimation of future work. Early forecasts could be achieved by replicating the historical pattern seen
Future work will be undertaken to correlate different types of teams, and different types of projects to determine if the patterns seen exists in a wider population.
Whilst it would appear that given the Median and Average of various types of teams is stable around 5 points estimating makes little sense. If forecasting is the only intent then that statement has merit, however the story point estimation plays a big role in selection of what work to attempt in a sprint. Team B and C for example carried many 20 point stories, but rarely attempted them in sprints in their original state. These higher estimates were always split into multiple smaller stories before starting the work. Estimation by the team played a key role in managing risk and allowed the team to make important trade-off decisions as late as possible. This is potentially valuable.
The patterns found were expected mainly due to the human bias of central tendency when faced with a set of options, in this case Fibonacci values of a fixed set. When faced with a set 1,2,3,5,8,13 and 20, groups would cluster around the center values. Given the tendency to like smaller rather than bigger work items and the ability to split work, erring on the smaller side was an inevitable outcome in the authors mind. Of course, there will always be outliers, but for the purposes of early forecasting, the most likely value to assume on average is 5 story points. The error in assuming 5 points would have been 10% error (actually, 7% in this data) against the eventual Mean values that emerged over time.
To Explore Further
We intend to provide a webinar on this topic in the future. If you would like to be invited, sign up below for “Webinars”.



Leave a Reply
You must be logged in to post a comment.