

Context: We measure progress and experiment with processes and products. However, experiments can take a long time, and failures can have huge costs. We have a lot of balls in the air, a lot of inventory to sell, and a lot of great stuff that isn’t quite done yet.
We have a problem …
We adapt too slowly …
Stakeholders, as a whole, make unsatisfiable demands. If we do not limit the work we start doing, we will likely miss deadlines, cancel many unfinished items, and waste effort by frequently switching our attention. This will unavoidably fail more stakeholders and squander more resources than if we focused our efforts on the most important things and refused to invest in less important things.
Forces
Several forces constrain a good solution. By better understanding those forces, we can craft a resilient solution that adapts rapidly to change.
- Congestion in specialized roles or equipment can lead to huge organizational delay.
- Amassed inventory in both physical and intellectual property creates organizational momentum that takes much effort to turn.
- Phased development accumulates sunk cost that earns nothing until a project is finally delivered.
- Our own cognition has limits, beyond which we lose creativity and make poor decisions.
- Modularization of teams working on a project creates dependencies that lead to significant lead-time delays.
Let’s explore these forces in detail.
Congestion
When we saturate a roadway, a production line or our personal calendars, things slow to a crawl. Here’s a quick test to see whether your company is agile: look at executive calendars. If they are full of meetings, the company is not agile. No one can rapidly sense the environment, adapt and create new things when their calendars are full.
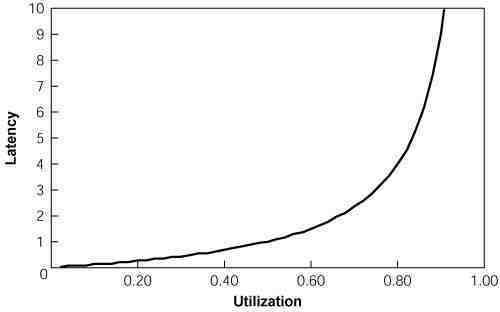
As randomly arriving requests increase a system’s utilization, the delay before a request is started (called “latency”) increases exponentially, per the graph above. The delay is caused by requests being queued up behind earlier requests. For example, members of a large marketing department might randomly request work from a graphics team. The graph shows the delay for a team that always completes a request in 1 time unit when there is no queuing delay.
Congestion creeps up on hard-working organizations, insidiously destroying their time-to-market. When a critical team or person is busy 50% of the time, requests take more than twice as long (roughly one unit delay, one unit to do the work); when busy 80% of the time, requests take five times as long; when busy 90% of the time, requests take ten times as long. Clearing such delays usually takes far longer than they took to create. Many managers become overly concerned when critical people or teams aren’t busy, and then destroy the organization’s time-to-market by loading them down with unimportant work.
Inventory
Assets are useful or valuable cash, things, people, or qualities controlled by a person or company, that we can use to meet debts and commitments. People are our best asset, so the saying goes, but only if we take advantage of their strengths: they are smart, we can delegate work to them and they can rapidly and independently adapt.
Some assets can help us weather periods of scarcity, but purchasing assets decreases cash reserves. The more assets we purchase, the less cash we have for immediate needs, such as to make products “just in time.” Fungible assets, fortunately, can usually be converted to cash for those immediate needs. But other assets, such as warehouses full of parts or equipment, cannot help us if we need cash to change direction rapidly.
Partial implementations are not easily converted to cash. Once they’re completed and put to use, they may provide a return on investment, but prior to completion they earn nothing. Few of us buy partially completed products; few investors buy stock in companies with “great stuff that hasn’t been delivered yet.” Until we spend even more resources to deliver these non-fungible, non-earning assets in usable form, we are stuck. If we are operating in a highly chaotic market or production economy, our non-fungible assets may herald our demise.
People who fear failure often advocate creating a more detailed plan for every project [bung2015]. But detailed plans take time to develop, they are situation-specific, and until their offspring become viable, they have no tangible value. The creative work they guide never produces exactly the intended economic benefit, and often the outcome is worse than we anticipated.
Creativity and economies are chaotic systems: we can roughly forecast what will happen in the short-term, but over time our forecasts tend to diverge exponentially from actual outcomes. So plans have more value when viewed as a guiding and evolving hypothesis than a mandate. A plan that demands enormous investment before we validate its assumptions creates enormous risk. Many expensive failures arise from failing to respect that plans lose relevance over time [char2005].
Most people have a cognitive bias called the sunk cost fallacy: after we invest time or money in a project, we tend to continue investing, even if we discover that we won’t get a decent return from the follow-on investment. Here’s a simple example: You buy a movie ticket for $10, you start watching the movie and in the first 10 minutes discover the acting is abysmal. You conclude you’d gain more pleasure doing something else. Most people will not walk out of the movie.
Our detailed plans are a sunk cost that can bias our decisions. We invested work creating a detailed plan, start executing the plan and then may discover that slavish adherence to the plan will likely generate a loss. Because we have invested so much time planning, we continue following the plan. In large organizations with highly structured job assignments, participants suffering from the sunk cost fallacy could fail to relay the information to leaders. The lack of bias in leaders is not enough to avoid this problem.
We can blame virtually every failed software project on sunk cost bias, on following a fixed plan or on both. From 1992 to 2005, over $10 billion was lost in abandoned projects, and these are the projects we know about [char2005]. The failure rate of software projects costing more than $1 million was 28% in 2011 [mier2012]. All these expensive, failed projects could have been structured to test market and production assumptions frequently, adapt based on discoveries, and abandon early if necessary to redirect those resources to more productive work. In doing so, they would have either succeeded or been canceled before they became depressing statistics.
Phased Development
Intuitively, people break down large projects into phases. In almost every creative project, we can see that one must design, prototype, build, test, package and deliver the creation. And so, following our intuition, we schedule these activities in a long sequence of specialized phases; this is called “waterfall development.” Unfortunately, this approach just intensifies the detailed plan/sunk cost problem. We can’t actually test our market theory until the creation reaches its market. But in normal, chaotic economies, chances are good we will discover we made a terrible mistake.
Instead of scheduling a large effort as a single long project, we could construct a series of short “release increments,” each providing increasing value to a stakeholder. There is a cost to this: the long project amortizes release costs over its entire lifetime, while the series of short projects incur release cost every time. Release increments work well only if we keep the release costs low.
The cost of incremental development can be much higher than waterfall. For example, projects often require testing to confirm the requested features operate properly. When we release a long project as a single release, we only have to test the system once (if we optimistically assume we can complete the project perfectly, without the need to retest anything). However, when we complete an effort in increments, changes in one increment could create defects in a previously completed and released function. So incremental projects often test every previously released function—this is called “regression testing.” At the beginning of the project, we don’t have much functionality to test, so testing costs are low. As the project complexity increases over time, the testing costs also increase.
Assuming regression testing cost increases linearly over the life of a project, the total cost of regression testing in an incremental project with n releases is (n + 1)/2 times the cost of a single waterfall testing run at project completion. So if a project will take 17 months, and we test every month, our testing costs will be 9 times the testing cost of a single waterfall release. When we recognize this problem in advance, we can reduce the testing cost through automation. Some include manual testing, integration and deployment work in a class of project dysfunctions called “technical debt” [yatz2009], because you have to pay the “interest” on lack of automated testing every time you do a release.
Projects that adopt an incremental approach without aggressively implementing automated testing, integration and deployment can inadvertently create an organizational crisis; which then either leads to organizational improvement (such as development of automated testing, integration and deployment tools) or to the outright rejection of incremental development. This perhaps explains the reluctance of many managers to fully implement Scrum, which requires frequent completion of a releasable product increment. Deliverable Sprint increments are one of the most important, and least implemented, aspects of Scrum.
Cognition
Organizations and people who rely on creativity must necessarily consider cognitive limits. In the modern world, we have whole departments of creative people—recruiters, engineers, marketers, lawyers, military strategists, etc. In fact, virtually all productive activity today involves the collaboration of creative people, since most mechanical activity has been automated. So managing creativity, cognition and interactions can determine whether our organizations succeed or fail.
Creative people often complain of being overwhelmed with worries; what they are complaining about is cognitive load. People can remember a maximum of between five and nine ordered concepts in one session [mill1956]. More than this and people start making mistakes. So when prioritizing work, creative people should be comparing at most about five projects [Chunk Before Choosing].
Late in the day, after making many decisions and during periods of low blood glucose, people experience reduced capabilities that limits their ability to choose [kahn2011]. This can have dramatic effects, such as the disturbing finding that Israeli judges grant parole at a 65% rate in the morning, but after a sequence of decisions, the rate drops to near zero [danz2011]. So much for even-handed justice.
Sleep loss has little effect on rule-based reasoning, decision making and planning tasks, but significantly degrades creativity and innovation [kill2013]. Working harder, if we are already exhausted, will reduce the quality of our creative work. It has long been known that industrial workers (relatively non-creative) are no more productive at 10 hours per day than they are at 8 hours per day; this led to the adoption of the 40 hour work week in the US [robi2012]. Creativity may suffer even more from overwork, which could explain the abundance of Foosball tables, video games and recreational facilities in highly creative and successful organizations.
People are more creative when they can focus without interruption. Research shows interruptions degrade creativity and quality [foro2014]. Related results show that multitasking can improve productivity within limits, but quality always suffers with increased multitasking [adle2012].
Procrastinators sometimes claim they are more creative under pressure. Research indicates this is false, with time-pressure leading to lower creativity. However, we can mitigate the creativity degradation from time-pressure by controlling the environment where creative people work, as the table below shows [amab2002].
| Time Pressure | |||
| Low | High | ||
| Likelihood of creative thinking | High | Creative thinking under low time pressure is likely when people are on an expedition. They:
| Creative thinking under extreme time pressure is likely when people are on a mission. They:
|
| Low | Creative thinking under low time pressure is unlikely when people are on autopilot. They:
| Creative thinking under extreme time pressure is unlikely when people are on a treadmill. They:
| |
Modular Development
Modular development decomposes a project architecturally into modules that share the same creative context, such as artisan skill set or operating environment. In doing this, we can employ specialists to produce each module. But each module cannot viably serve an external stakeholder on its own; instead, we must assemble multiple modules to resolve stakeholder needs. If we modularize a project, and do each module in succession, we usually cannot deliver value to a customer until all the modules are done. We may not discover defects in module interactions until after we assemble the entire system, which can cause developers to revisit modules long after they worked on them. This increases repair cost and introduces higher risk for late mistakes.
Building construction projects often use modular development, called design-bid-build in the trade [toxb2009]. Clients hire an architect to design a house, a soils engineer to assess the stability of the land, a foundation engineer to design the foundation, a foundation contractor to build the foundation, a framer to build the skeleton, a roofer to build the roof, etc. Until all these elements are complete, the house cannot be occupied. If we discover defects in the soils stability assessment late in the project, repairs may be extremely costly, perhaps even requiring demolishing the previous work,redesigning the foundation and rebuilding all subsequent elements of the building.
In short, modular development delays the release of value and significantly increases risk.
… therefore, limit work in progress to adapt faster
Work in progress (WIP) refers to inventoried materials and partly finished products that are not yet usable or delivered to stakeholders. We take a broad view that work in progress includes accumulated and unreleased work by large factories, by individual teams and by people.
In looking at ways to limit work in progress, let’s start with the agile individual, and work our way to larger groups.
- We can manage intellectual pursuits using distributed cognition, organizing ideas and commitments into work backlogs to focus our brains on the most important intellectual work.
- We can employ collaboration to more rapidly complete the most important work.
- We can recognize that idle workers are a natural part of a highly responsive organization, and we can use them to build capacity while keeping them available to manage demand.
- We can analyze the value chains in our production work to identify constraints, then apply back-pressure to reduce congestion and free resources to increase capacity in the constraint.
- We can restructure a project into independently viable release increments, and deliver those increments in series, allowing us to rapidly assess and mitigate market and production risk.
Let’s explore these solutions in detail.
Distributed Cognition
Several forms of personal agility embrace distributed cognition, a philosophy that recognizes that elements outside our brains—notes, books, reminders, computers, etc.—play an intrinsic role in cognition [clar2005].
A clear mind helps better prioritize work. Start by limiting your own cognitive WIP. David Allen claims that we must rid ourselves of mental clutter to create more effectively [alle2015]. Nagging worries that we will forget to complete tasks, pursue opportunities and mitigate risks clutter our minds and prevent us from concentrating on high priority work. A to-do list filing system called Getting Things Done (GTD) has been adopted by many.
Having a single filing system outside our heads to put all our concerns—which we can reliably consult for next-steps—helps us worry less. For example, when a worry or idea keeps us awake, we can stop ruminating on it by filing it in our system and going back to sleep, confident that we will address it later.
By focusing on the most valuable work, we can earn new assets that help us with less profitable work. Scrum teams order a list of work items, called a Product Backlog, by relative return on investment (profit). The most profitable (value/cost) items for the team’s current situation appear at the top, and others follow in decreasing profitability. Inter-item dependencies often create situations where it is more profitable to the team to finish a dependency before the thing that depends on it. But sometimes it’s more profitable to complete a superficial version of an item, that doesn’t require the dependency, because the superficial version can help us discover whether customers will buy the sophisticated version (this is the theory behind Customer Development [blan2012] and Lean Startup [reis2011]).
A discipline called Inbox Zero applies this Product Backlog idea to email [mann2007]. It asserts that email inboxes are not ordered by personal profitability (remember: economies don’t have to be about money, your economic profitability can value money, happiness, prestige, fun, etc.), and they take our valuable time and attention by remaining disordered. Therefore, we must filter and move email items from their disordered inbox state to an ordered state somewhere else. By processing our Inbox “to zero” routinely and rapidly, we limit our email prioritization work in progress and can focus on the most profitable work. To avoid getting stuck trying to decide where to put an archived email, many people put everything in a single folder called “Archive”. Modern email systems have sophisticated search capabilities that make this feasible, so it’s easy to find something specific even if it isn’t in a topic-specific folder. See [Cult of Zero: Free Your Creative Soul].
Scrum teams further limit work in progress by periodically creating a Sprint Backlog to contain work the team commits to addressing in the next increment. The Sprint Backlog, like the Product Backlog, should be roughly ordered by profitability as well, so the team attempts to work on the topmost item first.
Our cognitive limits argue that people should limit their attention to at most five to nine items at a time [Chunk Before Choosing]. Highly effective Scrum teams work on Sprint Backlogs that contain about five items, in my experience.
Cognitive limits also suggest creating fractally structured Product Backlogs (see [Product Owner]) to benefit product managers, architects, designers, marketers and other stakeholder rapidly see how projects could unfold. Near-term items are small; long-term goals are large. These fractally structured Product Backlogs also limit the amount of planning effort invested in a long project appropriately, thus radically reducing detailed planning effort (a dangerous form of waste), decreasing sunk cost bias and encouraging rapid adaptation to new information about markets and production.
Collaborative Focus
Scrum and XP teams swarm on the topmost (i.e., most valuable) items they are working on. This means that the team attempts to apply as many people on the topmost item as feasible, to maximize the likelihood they will complete that item by the end of the Sprint. The rest swarm on the next item, etc., until all team members are actively working. The goal is early item completion over keeping everyone busy, and team members are discouraged from starting something unlikely to be completed by the end of the Sprint.
Scrum and XP encourage teams to produce a shippable product increment at the end of every Sprint. This limits the production of work in progress and helps identify and limit technical risk. By actually shipping the product increment, we can identify and limit market risk, as well. When we adapt to what we discover, and create another product increment (in the next Sprint), we can mitigate those risks and improve both production rate and marketability.
Communication delayed can be a form of work in progress. Scrum provides for a very short daily meeting, called a Daily Standup, to limit delayed communication between team members. The longest delay for a critical conversation in Scrum is, ideally, one working day.
Idle Workers and Capacity Building
Limiting work in progress creates idle workers. This isn’t a bad thing: idle workers provide rapid response time when the organization needs it. But all responsible managers will ask whether they can employ idle workers to develop value while keeping response time low. The answer is Yes: workers can build greater organizational capacity when they are otherwise idle. But in employing response-time-critical workers, we must ensure that their capacity-building activities can be easily interrupted to avoid congestion and queuing. What can they do?
Automation can reduce the cost of repetitive manual labor and increase the organization’s responsiveness to the market. Idle workers can create automated systems to improve capacity and speed. Programming robots, 3D printers and other automated tools can help reduce the cost of manufacturing. Automating testing can help improve quality and reduce time-to-market in software development. Automated reports and spreadsheets can reduce the time and cost of understanding business metrics.
Specialists can create templates and teaching materials to help non-specialists perform acceptably in non-critical situations. The majority of most specialists’ work is relatively mundane; creating materials and training to make it possible to delegate that work can dramatically improve the overall quality of an organization’s products. Here’s a sample list to spark ideas: contract negotiation, architectural design, device setup, data warehouse interrogation, patent writing, web site SEO optimization, image cleanup, etc.
Idle workers can learn new skills. Managers can identify the skills most beneficial to the organization by employing Value Stream Analysis (see below). Highly agile companies cross-training employees to increase elasticity and reduce risk [canc2014].
Value Stream Optimization

Kanban boards track work by activity category and explicitly limit work in progress for each category. In the image, each category is a column. The column Bugs:Waiting has a work in progress Limit of 3 tasks. Two tasks are currently in Bugs:Waiting, so only one more could be accommodated. By limiting work in progress explicitly, and by making work visible, Kanban boards help keep work flowing to stakeholders. Organizations with highly specialized tools or individuals find Kanban easy to adopt. For example, in support organizations, people fixing bugs have very different skills from those dealing with customers. Responsible limits on work will consider the capacity of those different groups.
Value Stream Mapping exposes the steps and time taken “from concept to cash” to compute lead time [popp2006]. This can help identify places where work in progress limits will improve flow. Managers can pinpoint the constraints where excessive work in progress is creating queuing or congestion delays, and adjust work in progress limits upstream to eliminate queuing and congestion at each constraint. These limits can reduce lead time all on their own, by reducing congestion, switching cost and queuing. For people involved in the value stream, limiting work in progress also reduces cognitive load, allowing them to focus better and finish earlier. Note that we first reduce work in progress, pushing backward on work requests from a constraint to where work enters the system, telling requesters the system has no capacity for their request. Requesters can then buffer their requests if they choose, they may find a different approach to complete the request, or they may decide to do different work; regardless, we have helped our customer by giving them options. When we simply accept all work and queue it, we provide customers with fewer options and increase their risk.
By pushing back rather than accepting work to our queue, we will find that some workers have nothing to do. We can give them something better to do than create more risk or increase congestion, even if it’s doing nothing, but there is something better! If we limit work in progress from the constraint through all upstream sources (called “subordinating activities to the constraint” by the Theory of Constraints [gold1992] approach), it helps us easily find available resources and people that can help increase the capacity of the constrained activity and increase flow rate through the system.
Incremental Work
To limit work in progress, we can break a project into independently valuable pieces, work on those pieces successively and release them to stakeholders over time. Each completed piece must have some value, as a source of learning (such as to guide future development), of revenue, or of cost savings. This is called incremental development. A team that can independently produce an increment is called a feature team.
Any Scrum without working product at the end of a sprint is a failed Scrum. 80% of the scaled Scrum in Silicon Valley is in this category. They are “Agile in Name Only.” — Jeff Sutherland [lind2015].
Decisions between incremental and modular work must balance early value production against development cost: incremental development increases developer cognitive load and increases communication costs, but dramatically decreases market and production risk for the organization. Short increments promote learning and adaptation to accelerate projects and profit.
In large projects, managers often organize teams to focus on different modules, but this usually fails to limit work in progress. To propagate a change from a deep infrastructure module to an external stakeholder, elements must be handed from infrastructure team to dependent team, usually with a queuing delay. We can visualize this process using a dependency tree, and estimate lead times from that tree [gree2015].
Feature teams compress parts of a dependency tree into parallel efforts, and thus reduce lead time [vodd2008]. Organizing interteam communication to reduce conflicts, while allowing each team to run as fast as possible, becomes a challenge that must be met with a balanced approach.
Measuring Work in Progress
Work in progress is a leading indicator of delay (Degrandis 2017). Therefore, if a goal is to become more agile, measuring work in progress and constructing experiments to reduce work in progress will improve agility.
Examples
Pairing is a WIP limiting process that promotes greater collective responsibility. Every task gets two people assigned to complete it. The least skilled person of the pair does the work, while the most skilled person advises. In software development, this is called pair programming; the least skilled person uses the keyboard and the most skilled person looks over their shoulder and advises. Occasionally, the members switch roles to prevent burnout. A superficial analysis would argue that pairing must reduce the overall speed: after all, two people pairing could instead work in parallel. However, pair programming has been deeply studied, and a recent meta-analysis reveals that programmers operating in a pair generate higher quality code and produce more functionality than two individuals operating in parallel [salg2016].
Toyota uses several methods to limit work in progress, incorporating them into its corporate standard practices called Toyota Production System. One WIP limiting method is called Just in Time Manufacturing, a philosophy that avoids starting work until “the last responsible moment.” Here’s an example: A customer orders a car. The order taker converts the request to more narrow requests (body, chassis, drive train, wheels, tires, body paint) and schedules final assembly. Some workers then shape the body, other workers assemble the drive train, etc. When it first implemented this approach, decades ago, Toyota discovered its suppliers could not provide parts just-in-time. Tire manufacturers required that tires be ordered in advance and warehoused. But this would require Toyota to create “work in progress” that might not be used. Toyota began a program of training its suppliers to use practices from the Toyota Production System to limit WIP.
Today, Toyota’s pioneering practices are incorporated into the lean manufacturing field. But lean manufacturing practices address repetitive work and emphasize low-variation, which threatens creativity and limits experimentation. This cultural bias may explain why Toyota software engineers have been late to adopt Scrum and other agile software methods.
The building industry has a WIP limiting methodology called design-build (DB), where customers grant building projects to a single firm that does both design (architecture, engineering) and construction (foundation, framing, etc.). The construction team is engaged in the project before 20% of the design is complete. Very lightweight contracts are used, reducing penalties and shifting to time-and-materials approaches to allow for greater customer flexibility (Scrum proponents advocate a similar approach to contracts [kirk2013]). In the “traditional approach,” called design-bid-build (DBB), the customer first contracts with designers to create a detailed design of each component. Then the customer offers the design to construction firms for competitive bids. Intuitively, assuming the design won’t need to change (does this sound familiar?), DBB should deliver a lower priced outcome, due to competitive bidding.
But design-build has been found to be better than design-bid-build in every study we’ve seen. The Design-Build approach limits work in progress by bringing design and construction together, so they can adapt more rapidly to each other’s discoveries and limitations. Two studies indicate that Design-Build (DB) projects cost 6-12% less than Design-Bid-Build (DBB) projects, DB projects complete the construction phase 12% faster than DBB projects, DB projects deliver a usable building 30% faster than DBB projects (this higher delivery number arises from the high overlap of design and construction in DB projects). (Konchar & Sanvido 1998) [benn1996].
We can reduce work in progress by broadening specialist capacity. I have employed this strategy several times. I created written materials to help a client’s managers become agile coaches, the job I was hired to perform. They began to teach Scrum and agile techniques themselves. (I actually believe managers should take on this role.) I instituted a program where user-experience specialists taught engineers how to conform to a company’s user-experience standards. I wrote up accounting practices for capitalizing labor that could be followed by regular project managers and engineers. I did all this capacity-building work when my team members or I was otherwise idle.
Another example of limiting work in progress is this agile base pattern collection. I had grown concerned that organizations were failing to retain important agile behaviors long-term; executives and managers seemed not to understand the most fundamental aspects of agile, and I realized no one had collected those fundamentals in one place. I wanted to reliably teach people, teams and organizations to become sustainably agile. I started writing what I thought might become a book.
As I wrote, however, I realized I was accumulating work in progress, and then faced a decision: Do I release chapters for free as I write them? Would a book then be viable? Rich Mironov, a product management blogger and book author, assured me it would. I realized many patterns (this behemoth included) were far longer than traditional blog posts and longer than most patterns. I decided the point was to get the information out there, rather than craft everything perfectly before release; I can break the big pattterns up as I build a taxonomy of agile patterns. I am mostly writing when “between gigs.” How does this help me? The theory is this: While you can apply this approach yourself, you can do it faster if you involve someone with my background. And you now know how well I understand this field.
I suspect virtually every creative field has a set of WIP limiting methodologies. For example, some finance departments use an agile technique called Beyond Budgeting [hope2013], and at least one venture capital firm uses Scrum [suth2009]. If you know of other WIP limitation methods other than those mentioned here, please contact me.
Resulting Context
I like to call this the “Go small or Go home” pattern.
By limiting work in progress, we can more rapidly deliver useful work to help stakeholders and get useful feedback to help us adapt to their needs. We can more frequently [Proactively Experiment to Improve], which means we improve more rapidly. When we have done enough for our stakeholders, we can stop working on this project and direct our attention to the next-most valuable project. Each new work increment also helps us better understand and adapt to production realities. If we limit work in progress sufficiently, we can bring the most value from our people and resources and survive and thrive in chaotic market and production economies.
By limiting a system’s work in progress, we will likely discover that some equipment or people remain idle much of the time—these elements have zero work in progress from their local perspective. People unused to systems thinking can find idle resources or people appalling. If we don’t know what the organizational goals are, we tend to think “busy is better.” This explains why it is so important to start with organizational goals and then derive individual goals; it promotes systems thinking, and reduces the pressure to “keep everyone busy,” so we can focus on rapid delivery of organizational value. This was discussed in [Measure Progress with Leading Indicators].
Even after limiting a system’s work in progress, we will likely discover that some equipment, people, teams or departments continue to be busy. These elements likely constrain our throughput and extend our lead time. When elements are working at capacity, their request queues slow the system down. In the absence of situation specific needs, many people try to keep utilization of key elements below 80% [popp2006]. Thoughtful reallocation of idle equipment or people can also help reduce utilization. This creates system-wide elasticity to address heavy short term demand.
Counter-Examples
Earned Value Management
Earned Value Management (EVM) is a technique to judge the progress of a (typically) non-agile project in percent completion of work, and then assign a presumed value to the work so far completed (Earned Value Management 2018).
EVM does not require anyone to validate the assumed value of the project; agile approaches do this by delivering completed increments of value to the customer, and getting feedback from the customer. To limit the project risks that accumulated with EVM, some have proposed additional risk-analysis and management (Shah 2014), but this adds complexity to overcome a fundamental problem: work in progress is not limited by EVM.
EVM does not allow for mid-project changes in requirements. Some have replaced XP’s velocity metric with testable-requirements completion in EVM, and note that many aspects of agile practices, such as burn-down charts, look familiar (Nikravan & Forman 2010). However, this approach eliminates the most important advantage of agile approaches: they discover customer value early and allow for radical feature changes to produce the greatest value.
EVM is an approach that allows a supplier to get paid as it accumulates expenses, whether or not the supplier has delivered real value to the customer. When it is used, it leaves an option for not limiting work in progress, and so agile organizations (often governments) specifying EVM must also include protections to ensure frequent delivery and value testing.
References
Related Work
This pattern is the third in a series of five Agile Base Patterns. The first two patterns are Measure Progress with Leading Indicators and Proactively Experiment to Improve. The fourth is Embrace Collective Responsibility. You might be wondering about the fifth. Subscribe below to be notified when new posts go live.
Acknowledgements
Many thanks to Carsten Ruseng Jakobsen, Horia Slușanschi, Erik Gibson and Rick Zelinsky, who reviewed early drafts. Dan Greening remains solely responsible for errors in this work.