

Context: When unimpeded by outside forces, we rapidly adapt to circumstances and succeed, but this perfect independence rarely exists.
Problem: External factors limit our flow …
We don’t have the knowledge, specialty resources, elasticity or authorization to do everything ourselves, but relying on others puts us at risk.
Forces
When we operate in a system with many other actors, their dysfunctions can limit our own agility, despite extraordinary efforts. Worse, myopia may focus criticism on innocent contributors (possibly including us) and leave root causes of the problem dormant and unmitigated.
If we compete with others for services from dependencies (actors we depend on), it degrades our agility. The competition creates request queues that increase average latency, slowing us down, and increase variability, making our progress less predictable. Even when a dependency can start immediately, few may accurately forecast their own progress and even fewer will share those forecasts with us. Virtually all dependencies have some small risk that they will never complete [turi1936]. These unquantified dangers can damage or destroy our best efforts.
Our normal activities may not readily reveal why or how things might slow down. Work can be accepted into a system, and then get hung up internally. Whether inside or outside the system, actors may have limited visibility to these internal hang-ups. If no one understands the way the entire system works, no one may understand the cause of a potential or actual delay.
Dependencies
A system is comprised of actors (people, teams, companies, services). When we depend on an actor, it is a “dependency.” There are many types of dependencies. Each can slow our ability to sense, adapt and create, and therefore damage our agility.
Strode and Huff identified three main dependency classes: Knowledge, Task and Resource. When such dependencies occur intra-actor, the [Collective Responsibility] pattern provides a solution to mitigate their effects. However, when an actor depends on other actors, we have limited power to prevent delay.
Knowledge dependencies focus on the capabilities of an actor; a project cannot proceed until the actor gains knowledge. A requirement dependency prevents progress until the actor obtains necessary domain knowledge by surveying or experimenting with stakeholders. An expertise dependency prevents progress until the actor gains technical, design, or domain expertise. A task allocation dependency prevents progress until responsible parties are identified and assigned. A historical dependency prevents progress until the actor understands more about past decisions.
Task dependencies focus on task sequences. An activity dependency prevents progress until a particular development activity is complete (such as rendering a graph after receiving data from a user). A business process dependency arises when business policy dictates how activities must proceed (such as that documents must be examined for copyright issues at a particular development stage). Delayed approvals from lawyers, planning commissions, executives and other signatories can limit our ability to sense, adapt and create rapidly in response to changing conditions.
Resource dependencies focus on other actors or components; something cannot proceed until the resource is available. An entity dependency prevents progress until a particular person, place or thing is available. A technical dependency prevents progress until a capability is realized in technical infrastructure.
Dependency Chains
A long dependency chain can mask the primary causes of delay. Most of us suffer the recency effect, a cognitive bias that blames recent activity for problems. For large projects one of the most common causes of delay is late-staffing and failing to shift the forecast delivery date [mage2015]. People often forget this when the deadline arrives.
When final shipping delays occur, superficial analysis rarely reveals the real causes: deep, structural or ancient problems. In projects with complex dependencies (such as aircraft construction or software development), infrastructure components can dramatically influence delivery dates months or years hence. I recently investigated dependency problems in a large software organization; the deepest infrastructure component caused no delays, but the second deepest (even harder to discover) created many months of delay.
In some actors, the first production steps have no delay, giving them confidence to accept new work without hesitation, but the limited capacity of later production steps creates large internal queues. The apparent simplicity of a request can lull the supplier and the consumer to assume progress will be smooth. No one realizes constraints hidden by layers of dependency can grossly extend the lead time (the time from a request’s arrival to its satisfaction).
Collective responsibility in internal team members can increase our own agility, perhaps motivating us to build a cross-functional team, but what motivates outside actors to help? Rigid, specific, long-term supplier contracts can promote compartmentalization, limiting their perceived responsibility for our success. Compartmentalized responsibility limits moral agency [rozu2011], de-motivating other actors. Organizational policies that emphasize narrow accountability thus can interfere with agility.
Supplier risks can dramatically affect us, but can remain hidden behind confidentiality. If a supplier reveals their known risks, they could motivate their customers to find less risky suppliers, or equip their customers to reveal their risks to competitors. And yet, customers may have skills or information that can help reduce suppliers’ risks. How can we improve risk mitigation without threatening suppliers?
Each additional dependency reduces choices in ordering work, increases expected lead time and creates more friction between teams due to misaligned priorities [mage2015].
Power Dynamics
Acting alone, we can sometimes research systemic root causes ourselves, discovering unvarnished truths about other actors or interactions. We can sometimes act alone to fix the problems. By revealing truths, we can often embarrass dysfunctional actors to make short-term improvements, or convince a boss to command someone to respond more rapidly or comply with a more agile practice. The subordinate may not understand why the practice is important—”The boss says we must be agile, so I’m doing this thing, but I don’t know why.” The problem gets fixed now, but may recur later.
In acting alone, we trade-off sustainability for speed; problems seem to get fixed faster. Unfortunately, some who helped us discover more about the system may be harmed by our fixes; they may get no credit for helping us, or get marginalized by the potential cure. Growing resentment in victims can lead to our own marginalization or elimination, or, at least, discourage others from coming to our aid. As we say in the business, “A dead agilist is a useless agilist.”
… therefore, collaborate to fix systemic dysfunctions.
Even when we think we deeply understand the system in which we work, we should engage other actors in a community devoted to analyzing and understanding the system. When we don’t have direct authority over other actors, we must inspire, educate and convince them to identify and help mitigate external dysfunctions. We must obtain access and consent.
Collaboration can solve the problem, but only after actors understand the system, the problem and the systemic dysfunctions that led to the problem. They must believe proposed solutions will fix the problem and not harm them. The unfortunate early history of agile is marred by impatient bomb-throwers, who insisted that agile meant “Fire all the managers.” Generously speaking, agilists meant that managers should transform themselves to be teachers, mentors, coaches and individual contributors. However, unwitting managers heard direct threats to their hard-earned careers. This approach has proven self-defeating, with many large agile implementations stalled or reversed by fearful managers resisting change.
Therefore, we must teach, collaboratively analyze and collaboratively experiment, if we seek to change a system from within. This has led to a significant agile coaching profession; it appears to be the safest way to sustainably change an organization.
- We must teach everything we know. Since agility is our goal, participants must understand how agility helps them. Agility serves to help us more rapidly sense, adapt and create to meet the demands of a chaotic economy. The Agile Base Patterns provide a broad, guided approach to agility that most people can appreciate; teaching them may be a fruitful way to engage all actors in a system.
- We must analyze the system together with stakeholders. We can teach collaborative analysis techniques, some of which are discussed in this pattern. They are designed to not only reconcile discordant perspectives, but give every participant a stake in the outcome.
- We must develop countermeasures together, with a mutually held goal of improving the system’s health. Metric alignment methods can help, see [Measure Economic Progress].
- We should distribute credit to as many actors as possible, to align their personal interests with a successful outcome.
We must investigate systemic problems from the perspective of a coach. Coaching is, of necessity, a holistic exercise [adki2010].
The remainder of this pattern discusses specific social analysis and mitigation strategies that engage actors that may be outside our direct influence.
Analysis
When we operate within a large system, normally we want to focus on our work to avoid distractions and delay. However, if no one has a broad understanding of dependencies in the system, we should take responsibility to analyze the system and share our discoveries broadly. Too often cognitive biases cloud our judgment, and so we should not stop at a superficial analysis. To understand system dependencies, consider two approaches: static and dynamic.
Crowdsource and Combine
The most creative collaborations often arise from people first brainstorming solutions independently, without the bias introduced by others, and then combining those thoughts as a group—clustering, filtering and reconsidering them into a coherent whole. The Crowdsource and Combine meta-pattern is used throughout the Agile Canon, for Planning Poker, Bulk Estimation, Retrospective meeting brainstorming sessions, etc. It was used in the 1960s to combine expert opinions into a more accurate result [dalk1963]. (It is also fundamental to many parallel computing architectures, such as map-reduce.)
Crowdsource and Combine aligns the personal interests of participants with a collective solution: if the solution is adopted, they can take some credit for the collective solution. This engages actors, who may not be otherwise motivated, with the solution.
Root cause mapping
Using the technique of “five whys”[ohno1988], individuals can identify root causes—hidden dysfunctions or contributing factors that led to the problem. We first state the problem, then list the immediate causes of that problem to create “first level causes,” then list the causes of the first level causes to get “second level causes,” and continue until we have obtained a fifth level of causes. With this depth, we have identified most contributing factors. We can compose this into a directed graph, sometimes called a cause map or a fishbone diagram.
We can use the Crowdsource and Combine pattern to get a more complete, nuanced result embraced by more actors. In this approach, we gather all stakeholders to a problem and solicit their suggested causes to deeply understand the many causes, identify the most effective fix and resolve the problem [Social Cause Mapping]. Edward de Bono’s Six Thinking Hats approach is another example of the Crowdsource and Combine pattern [debo1999].
Analyze statically
Static dependency mapping and analysis help us understand and reorganize actors to reduce work-in-process, reduce lead time and increase quality [23].
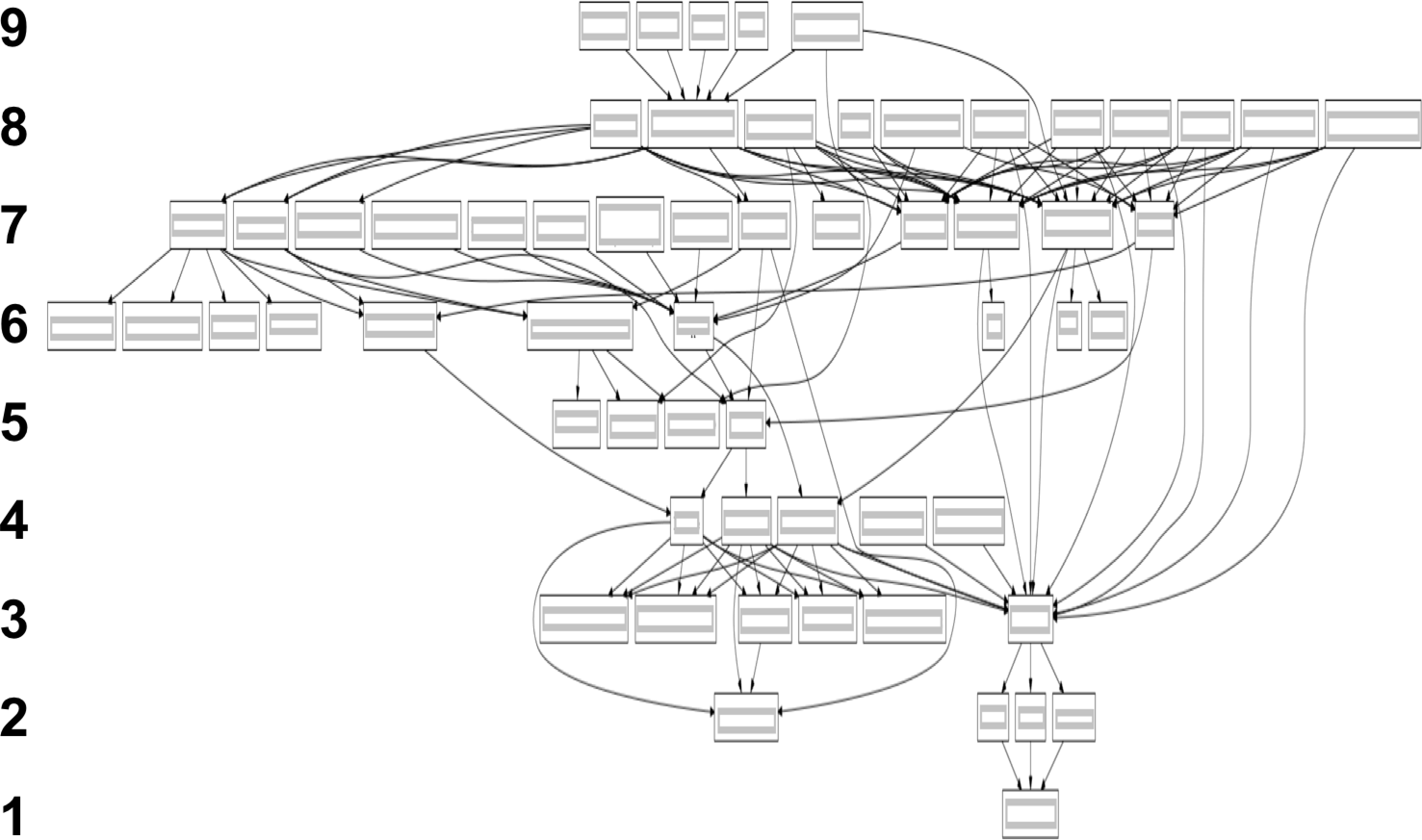
Figure 1. Dependency diagram
For example, the figure above shows the dependency graph of a large software system. Level 1 in the graph has only one infrastructure component, a shared infrastructure library. When we change something in that infrastructure component and release it, the component must be consumed, incorporated and released by each successively higher component in the dependency chain. In this case, changes are not available to system users until released in Level 9 components. Level 9 includes 5 client components, front-end software for applications running on personal computers, mobile devices or web user-interface servers.
If each component works in isolation using Scrum, we can compute the minimum lead time for a requested feature to reach a stakeholder. The simplest heuristic is to count the number of levels required to reach a stakeholder, and multiply it by the time required to complete each level. When someone requests a minor user-interface change, we may only need to change components at level 9; in that case, we compute the time to complete just that level.
If component requests are synchronized, they reach a team immediate before its Sprint cycle began and deployed immediately after, and the component lead time is one Sprint cycle. In the worst case, a request arrives just after the cycle begins, and the component lead time is two Sprint cycles. On average, an unsynchronized request will arrive midpoint into a team’s Sprint, and so the expected lead time is 1.5 Sprint cycles, 50% more due to unsynchronized requests.
You may have to use a different value than a team’s declared Sprint cycle: it should be the total time to produce a releasable product increment—I call this the True Sprint Length [gree2015]. Scrum’s rules require teams to produce a releasable product increment in each Sprint. Because short Sprint cycle times are usually seen as “better,” teams sometimes declare an aspirational Sprint cycle time in which they cannot responsibly succeed. In conversing with teams to create this graph, I discovered several who required a minimum of 8 weeks to complete and test the work, despite claiming a Sprint cycle time of 2 weeks. Jeff Sutherland similarly found less than 25% of so-called Scrum teams he encountered in Silicon Valley could deliver working code to stakeholders after every Sprint [suth2015].
Aside: I advise teams whose true sprint length differs from their declared sprint length to increase their declared Sprint cycle time to match the true sprint length. Once this is done, the team can use the Sprint cycle time as an economic progress metric [Measure Economic Progress], to be assessed and improved in Sprint Retrospective meetings. Teams that have followed this advice have radically improved their production speed and quality.
Armed with the True Sprint Length of each team, we can first compute the in-process time to deliver a simple change to a stakeholder. To compute the in-process time, start with the lowest level components that must be changed. Add each component’s True Sprint Length on the longest path from lowest affected component until we reach the stakeholder.
If all teams’ Sprints are synchronized (the output of a lower-ranked team is immediately used by a higher-ranked team), the total lead time is the in-process time plus 50% of the first team’s Sprint length (to account for a request being made mid-Sprint). But in most large organizations using Scrum, Sprint cycle times are not synchronized. Practical concerns inhibit synchronized sprints: there may not be enough meeting rooms to accommodate all Scrum teams meeting simultaneously; some teams require more time, others less; and some people may need to attend multiple teams’ meetings. We can solve for the total lead time in an unsynchronized system by simply adding 50% to the in-process time.
In the example of Figure 1, if every team in our graph has one-month synchronized sprints, the total lead time for a simple change at the lowest level team is 9.5 months. 0.5 months because the request arrives randomly during the lowest level team’s sprint cycle plus 9 months for in-process time from the lowest team through each of the 9 levels to the customer. If the teams have one-month unsynchronized sprints, the system lead time is 13.5 months.
Gathering Data
The first time I assembled a static dependency graph, I interviewed every engineering manager in a large company. These discussions were valuable, but map construction took weeks.
The second time I assembled one, I realized Crowdsource and Combine could speed it up. I followed these steps:
- I invited several product architects, leaders and managers to a meeting.
- Prior to the meeting, I wrote the name of every team in the product engineering group on a separate sticky note.
- At the meeting, I first asked everyone to look at the sticky notes, independently consider which teams might be missing from the list, and write them down.
- I then asked attendees to rearrange the stickies on a white board so those that depended on no other teams were on the bottom, and those that no team depended on would be on top. I asked them to remain silent.
- I asked attendees to draw arrows from each team to the teams it depended on.
- We then opened it up for conversation. It turned out that there were some dependencies in question, and attendees agreed to revise the results by email.
- I took photographs of the board, transcribed to a graphing application, and asked for corrections.
This time, data gathering and assembly took only two days. The participants became more engaged in the process.
Reorganize structurally
Static dependency graphs not only provide a rapid understanding of component architecture and a forecast of organizational limits on delivery time, they also help leaders make better reorganization decisions.

Team merger candidates
For example, on the graph above, we highlight component teams that might be easily merged to reduce the system lead time. The circled group on levels 9 and 8 includes clients running on different devices (row 9) and a shared library (8). The circled 6-5 group comprises two middleware teams created by splitting one overly large team. The circled 4-3 group was a data transport team (4) and a data assembly team (3). The circled 3-2-1 group included a data assembly team (3), compression teams (2) and an extraction team (1).
Managers noted that the circled 6-5 middleware teams were familiar with each other’s code, making reorganization easy. So, we decided to restructure these two teams to be “feature teams” operating off a single backlog and working in parallel [larm2008]. This eliminated the (5) team and shifted all the teams in rows 4 through 1 up a row, reducing the system lead time by 1.5 months. It required virtually no work, and reduced work in process by 1/9 = 11%. Without a dependency graph, we would never have found this opportunity.
Involving stakeholders in analyzing the problem and constructing a solution led to systemic changes. However, the solo work I did with a previous system, also revealing opportunities for structural improvement, but resulted in no known changes. Collaboration is important.
Analyze dynamically
Dynamic techniques analyze the flow of activities through a system. Value stream mapping reveals the value-add time, the non-value-add time and the queuing time for each actor in creating value “from concept to cash” [mart2013]. We can then identify and mitigate systemic problems. Minor organizational changes to flow can often dramatically reduce lead time and improve other systemic progress metrics.
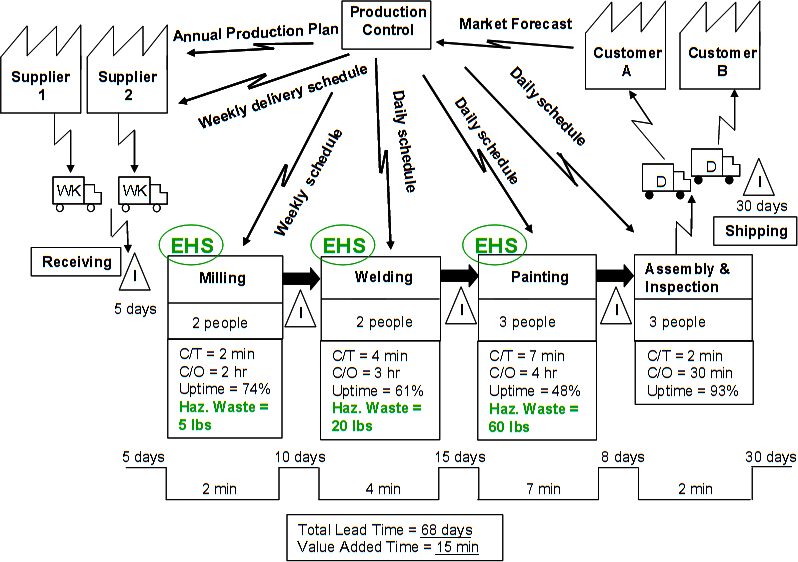
Value stream map with environmental data (US EPA)
The example above shows a simple value stream map for creating a part, with additional information on hazardous waste.
Value stream maps can be constructed using Crowdsource and Combine. Value stream maps for large organizations, in my experience, are best constructed with a group, because no one person typically knows all the specifics about every step and dependency. For example, Tom Wujec uses Crowdsource and Combine to develop thoughtful value stream maps for toast making [wuja2013]!
Reassign people and resources
The Theory of Constraints method [gold1992] uses Value Stream Mapping to understand a system, examines queue lengths to assess component constraints, then shifts resources from the least constrained components to the most constrained. In a creative process, this approach would suggest creatively retraining and repurposing people and equipment.
For example, in one company I was asked to improve the Data Science department. I coached department members to construct a Value Stream Map, starting with a request for a new business report. The map revealed a loop between business analysts and data warehouse architects. A long queue of requests for architects to create and approve schema changes added 2 months (!) to the lead time for new reports. We asked the VP Engineering to fast-track approval for a new schema design tool; it allowed business analysts to safely experiment with new schemas. The data warehouse architects trained business analysts to design schema changes that were compatible with the existing system. They received mostly-valid schema change requests that required much less review time. The lead time for new reports dropped by more than a month.
Culture
Teaching and Coaching
Teaching agility to external actors has many advantages. It helps them not only eliminate the dysfunctions that concern us now, but prevents others from arising later. Toyota famously taught its suppliers to use just-in-time manufacturing, an agile manufacturing process, because the suppliers were limiting Toyota’s agility [ohno1988]. As a side-effect, this eventually built out a infrastructure of just-in-time in Japan that accelerated its recovery from WWII.
To my knowledge, all sustained agile implementations have a teaching and coaching program. When agile teaching and coaching stops, well-aligned leading indicators stagnate, work-in-process increases and experiments become uninspired. Here are the typical functions of an agile teaching and coaching program:
- Teaching whole departments, including managers, an agile approach, such as Scrum, Lean Startup, XP, Kanban and/or the Agile Base Patterns.
- Incorporating an agile introduction into employee on-boarding activities.
- Making teaching and mentoring a routine activity in everyday work.
- Coaching individual teams, particularly by involving a coach in Retrospective activities, where past history, future experiments and process improvements are discussed.
Early in an organization’s agile journey, it may employ contract coaches to perform teaching and coaching roles. This rapidly introduces experience from multiple sources (the contractors’ former clients) into the organization’s advancement. However, organizations may gain cost savings by later employing permanent staff coaches. Permanent staff coaches can succeed, if they are encouraged to attend conferences and courses; they can gain much of the breadth of a contract coach by learning from them regularly. However, in my experience, organizations that do not invest sufficiently in the continuing education of their agile coaches and trainers lose agility over time.
Hiring and Promotion
Hiring and promotion policy limits agility in most organizations I’ve worked with.
Organizations sustainably improve agility when managers demonstrate agile characteristics in their own work. Some people comfortably apply metrics, experiment and limit their work in process (so they can focus), taking personal responsibility and collaborating; these characteristics produce the conditions needed for sustained, improving agility. Individual contributors in an agile organization need not necessarily exhibit these characteristics, but their managers (anyone working intimately with process or organization)—including Managers, Directors, Executives, ScrumMasters, Architects, Creative Leads, Product Managers and Project Managers—should. Hiring, promotion and employee development policy must change if we hope to sustain agility long-term.
Organizations that make managerial careers attractive only to people with good managerial skills, get managed better. Managers and highly contributing individual contributors should be paid equally. Regrettably, in most organizations, managers get paid more than individual contributors. The theory is that managers are more highly leveraged than individual contributors. However, this is certainly nonsensical in software companies, where strong contributors outperform their average peers in writing software by far more than their salaries vary [boeh1981]. This perversely attracts (or I should say, distracts) good individual contributors to become mediocre managers. The yearly Gallup study State of the American Manager, has long pointed that highly productive organizations place only people with strong management talents in managerial roles [gall2015]. I have discussed how effective agile managers have more advanced talents than the high-talent managers identified by Gallup [Agile Managers].
Hero cultures that laud individuals for “above and beyond” contributions can also destroy agility. In one client, employees (including engineering managers) were rewarded for showing that their personal efforts led to software successes. This led people to seek opportunities to show that they were the most qualified developer in their teams. Unfortunately, the hero culture interferes with collective responsibility. Managers in this organization felt conflicted: should they coach their employees to be more technically competent than they are, or should they allow them to fail and fix their problems later? Individual contributors, who wanted to demonstrate how their specialization led to success, avoided teaching new skills to colleagues. When work demands shifted, the specialists gained importance and higher salaries, but the teams slowed.
These factors may seem minor when dealing with small teams in an organization. However, as teams become more agile, employees eventually discover the contradictions between corporate HR policy and agility. In my experience, employees openly discuss these contradictions. If the organization fails to fix the dysfunction, employees will resist using agile practices further and this will lead to the elimination of agility.
Of course, the best approach to changing HR policy is teaching and coaching HR personnel and managers the agile base patterns, as well as the diagnostic and resolution skill described here. The most success I obtained in changing HR policy was in an organization where I first taught agility to HR leaders, then worked side-by-side with them to re-craft career ladders and performance review criteria.
Exercises
- With a colleague who shares your opinion, think about most frustrating problem in your company. Construct a root-cause map. Are there a couple of easy fixes that would prevent this and other problems from recurring? What dependencies are revealed by the map? What are the motivators for those actors? Is there a way to align their interests to produce a better result?
- Consider how solutions are created in your organization. Are there groups focusing on different “modules”? If so, draw a static dependency diagram. Are there modules near the bottom that most other modules depend on? Do they produce low-quality results (that require rework) or are they slow? If so, how does that affect the rest of the organization? Do leaders in the organization know about this, or are these hidden problems?
- Do some solutions in your organization require stages of activity? If so, construct a value stream map. Are there some steps that take a long time, but don’t require much actual work? Can we shorten the delay or completely eliminate the step, by changing the process?
Resulting Context
In applying this pattern, the system in which we operate becomes more agile. When other actors respond more rapidly and effectively, our own agility improves. We may interact more frequently with other actors. We may merge the activities of dependencies into our own work. We may find that long-standing problems disappear.
Sustained agility depends on healthy teaching and coaching activities. Thus, a healthy organization will support monitoring, teaching and coaching new approaches to agility; this can be through contract coaches or in-house employees. In my experience, organizations that use in-house employees as coaches or teachers should provide ongoing learning opportunities and long-term career growth; otherwise, their skills will grow stale, and likely they will leave.
Related Patterns
The five Agile Base Patterns are described in detail at Senex Rex. See Measure Economic Progress, Proactively Experiment to Improve, Limit Work in Process, Embrace Collective Responsibility and Collaborate to Solve Systemic Problems. Subsequent posts will explore patterns beyond these basics. Subscribe below to be notified when new posts go live.
References
[mage2015] T. Magennis, personal communication (2015).
[adki2010] Lyssa Adkins, Coaching Agile Teams: A Companion for ScrumMasters, Agile Coaches, and Project Managers in Transition, Addison-Wesley (2010).
[ahi1984] Ahl, David H. (March 1984). “Osborne Computer Corporation”. Creative Computing (Ziff-Davis). p. 24. Retrieved 4 April 2011.
[boeh1981] B. W. Boehm, Software Engineering Economics, Prentice-Hall (1981).
[boeh1988] B. W. Boehm and P. N. Papaccio, “Understanding and Controlling Software Costs,” IEEE Transactions on Software Engineering
14:10 (October 1988).
[dalk1963] Norman Dalkey, Olaf Helmer, (1963) An Experimental Application of the DELPHI Method to the Use of Experts. Management Science 9(3):458-467. http://dx.doi.org/10.1287/mnsc.9.3.458.
[debo1999] Edward de Bono, Six Thinking Hats, Back Bay Books (1999), ISBN 978-0316178310.
[gall2015] Gallup, 2015 State of the American Manager (March 27, 2015).
[gold1992] E.M. Goldratt et al, The Goal: A Process of Ongoing Improvement, 2nd revised edition (1992).
[larm2008] Craig Larman & Bas Vodde, “Choose Feature Teams over Component Teams for Agility,” InfoQ, http://www.infoq.com/articles/scaling-lean-agile-feature-teams (Jul 15, 2008).
[lead2009] Lead, http://www.duke4.net/comment.php?comment.news.267, 2009.
[mart2013] K. Martin et al, Value Stream Mapping (2013).
[ohno1988] T. Ohno, Toyota production system: beyond large-scale production (1988).
[rozu2011] Cécile Rozuel, “The Moral Threat of Compartmentalization: Self, Roles and Responsibility,” Journal of Business Ethics (Sept 2011).
[stro2012] Diane E. Strode and Sid L. Huff, A Taxonomy of Dependencies in Agile Software Development, 23rd Australasian Conference on Information Systems (3-5 Dec 2012), Geelong, Association for Information Sciences.
[turi1936] Alan Turing, “On computable numbers, with an application to the Entscheidungsproblem,” Proceedings of the London Mathematical Society, s2-42 (1937), pp 230–265, doi:10.1112/plms/s2-42.1.230. Alan Turing, “On Computable Numbers, with an Application to the Entscheidungsproblem. A Correction,” Proceedings of the London Mathematical Society, s2-43 (1938), pp 544–546, doi:10.1112/plms/s2-43.6.544 . Free online version of both parts: http://www.turingarchive.org/browse.php/B/12.
[wuja2013] Tom Wujec, “Got a wicked problem? First, tell me how you make toast,” TED Global, http://www.ted.com/talks/tom_wujec_got_a_wicked_problem_first_tell_me_how_you_make_toast (2013).
Acknowledgements
Author
Daniel R Greening