-

Forecasting without Historical Data
We can forecast even when no historical data exists, if we use our experience and judgment. In Part 1 of our probabilistic forecasting series we looked at how uncertainty is presented; in Part 2 we looked at how uncertainty is calculated. Both of those parts presumed historical data was available. Although estimating without historical data…
-

Probabilistic Forecasting
In Part 1 of this series we discussed how probabilistic forecasting retains each estimate’s uncertainty throughout the forecast. We looked at how weather forecaster’s present uncertainty in their predictions and how people seem comfortable that the future cannot be predicted perfectly and life still continues. We need this realization in IT forecasts! In Part 2…
-
Forecasting Defined
This is the first article in a series that will introduce alternative ways to forecast date, cost and staff needs for software projects. It is not a religious journey; we plan to discuss estimation and forecasting like adults and understand how and when different techniques are appropriate given context. Stakeholders often ask engineers to estimate…
-
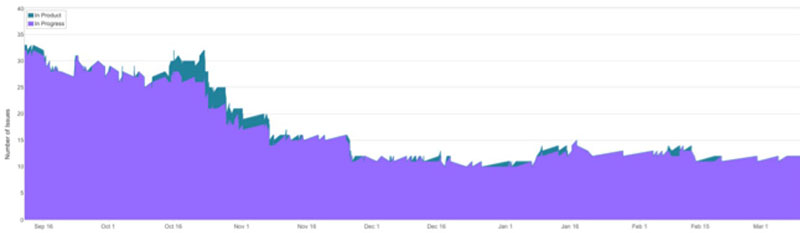
Breaking into Quality: Prioritization as a Pitfall
Our team kept solving the easy stuff, the big deliverables seemed to take forever, and would inevitably come out with major bugs. Do the right things right… Why not just do that? For any one product, a number of people and processes come together. We automatically operated by priority, and this turned out to be the…
